华泰证券:DeepSeek是否会改变AI投资范式?
核心观点
事件:DeepSeek发布R1,引发资本市场对算力增长展望的担忧
1/20,DeepSeek发布R1模型及相关应用,以较低的训练成本达到与现有前沿模型相当的效果,引发市场对算力投资的担忧。我们认为:1)DeepSeek主要创新是通过在预训练阶段加入强化学习,DeepSeek V3训练成本相当于Llama3系列的7%,对当前世代AI大模型的降本做出了重要贡献,有望降低现有模型的训练和推理成本;2)目前北美四大AI公司主要通过扩大GPU集群规模的方式探索下一代大模型,DeepSeek的方式是否在下一代模型研发中有效还有待观察。3)DeepSeek这次的成功显示,在Scaling Law放缓的大背景下,中美在大模型技术上的差距有望缩小。
思考#1:DeepSeek R1对当前世代大模型降本做出重要贡献
据DeepSeek V3技术报告,V3模型的训练总计只需要278.8万 GPU小时,相当于在2048卡的H800GPU集群上训练约2个月,合计成本约557.6百万美金,相较而言,Llama 3系列模型的计算预算则多达 3930万 H100 GPU小时,DeepSeek训练成本约相当于Llama 3系列模型的7%。我们认为:1)DeepSeek R1通过在预训练阶段使用强化学习,在仅有极少标注数据的情况下,提升了模型推理能力,能够大幅降低训练成本,实现和现有大模型(如o1)相当的效果。如果Meta等采用DeepSeek的路径,或降低现有模型的训练成本。
思考#2:DeepSeek的方法在探索下一代大模型上是否有效尚不可知
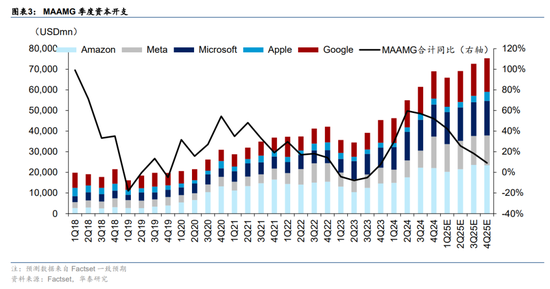
根据Factset一致预期,2024年,微软、谷歌、亚马逊、Meta、苹果等北美五大科技公司合计资本开支2253亿美元,2025年有望继续增长19.6%。其中很大部分投入是用在包括GPT-5、Llama4等在内下一代模型的算力投资。目前北美四大AI公司主要通过扩大GPU集群规模的方式探索下一代大模型。如1/21宣布的The Stargate Project所显示,下一代大模型所需的算力可能达到百万卡集群的规模。DeepSeek的方式是否在下一代模型研发中有效还有待观察。
思考#3:Scaling Law放缓大背景下,中美技术差距有望缩小
2022年11月,OpenAI发布GPT3.5以来,中美在大模型技术上的差距出现扩大趋势。进入2024年下半年,随着互联网文本数据的耗尽,预训练阶段的 Scaling law 面临挑战,最先进大模型的发展出现放缓趋势。过去两年,中国涌现了包括智谱、月之暗面、Minimax等初创企业。这次DeepSeek R1受到广泛关注,显示随着最先进模型发展放缓,大模型的竞争从探索转向工程创新,中美技术差距有望缩小。



风险提示:
1)中美贸易摩擦升级,影响产品供需与公司海外布局风险。
2)宏观经济下行风险。
3)创新品渗透不及预期,导致公司增长不及预期。
4)本研报中涉及到未上市公司或未覆盖个股内容,均系对其客观公开信息的整理,并不代表本研究团队对该公司、该股票的推荐或覆盖。